
Ich hatte aufgrund einer Empfehlung am 29. Juni etwas bei Pearl bestellt. Im Formular hatte ich natürlich die Ankreuz-Kästchen für die ganzen Newsletter leer gelassen, wie ich es immer mache.
Am 4. Juli kam der erste Werbe-Newsletter. Am 5. Juli kam die Rechnung für die Bestellung, die zu diesem Zeitpunkt noch nicht einmal angekündigt war. Am 7. Juli kam der nächste Newsletter. Also wurde ich ein wenig pissig. Ich antwortete, daß ich keinen Newsletter bestellt habe und deshalb auch nicht nachsehen muß, wie ich ihn wieder loswerde. Die Antwort kam umgehend:
> Bitte antworten Sie nicht direkt auf diese Nachricht. Nutzen Sie bitte unsere Service-Adresse. <
Nein, es war keine „noreply“-Adresse gewesen. Im Namensfeld stand sogar ein Klarname.
Also ging das ganze nochmal per Forward an die Kundenservice-Adresse mit dem Begleittext:
Ich habe keinen Newsletter bestellt. Und nein, ich muß auch nicht nachsehen, wo ich mich austragen kann. Sie tragen mich ein -> Sie tragen mich aus. Und nächstes Mal tragen Sie mich nicht mehr ungefragt ein. So einfach.
Unbestellter Newsletter-Spam führt dazu, daß ich nicht mehr bestelle.
Den Spam-Score meines SpamAssassin könnten Sie sich auch mal ansehen. 4,7 von 5,0 Punkten, gratuliere, knapp an der Spam-Erkennung vorbeigeschrammt.
Und nochwas: Wenn man an eine Absender-Adresse nicht antworten soll, hat diese gefälligst mit „noreply@“ anzufangen.
Eine gute Stunde später bekam ich eine Ladung Mails – Austragungsbenachrichtigungen für folgende Newsletter und Listen:
- HotPrice Mails
- MegaDeal-Mails
- Geburtstags- & Jubiläums-Mails
- Saisonale TOP-Empfehlungen
- Infos zu erworbenen Produkten
- Infos zu Verbrauchsmaterial
- Service-Kommunikation per E-Mail
Danach kam eine Textbaustein-Mail, daß meine Adresse für weitere werbliche Nutzung gesperrt worden sei. Und wenn ich „zu unserem Bedauern“ meinen Account löschen wolle, müsse ich nochmal an deren Datenschutz-Adresse schreiben. Dieselbe Mail kam fünf Minuten später nochmal.
Also: Wenn man bei Pearl etwas bestellt, wird die Frage nach den Newslettern offenbar nur zum Schein gestellt. Egal ob man was ankreuzt oder nicht: Man wird auf jeden Fall bis auf aktiven Widerruf mit den Newslettern beschickt. So kann man natürlich auch ausdrücken, daß einem Kundenwünsche scheißegal sind.
Nachdem ich die Rechnung bezahlt hatte, wurde die Sendung losgeschickt, obwohl es in der Mail mit der Rechnung geheißen hatte, sie sei schon unterwegs. Und dann wurde meine Weiterleitung zur Packstation abgelehnt.
Es passierte, was passieren mußte: Der Bote klingelte gestern zwar, aber weil ich nicht um-ge-hend! die Treppen aus dem 5. Stock runtergerannt bin, nahm er das Paket wieder mit und warf es in einem DHL-Shop ab. Mobilitätseingeschränkte Menschen existieren für DHL ja nicht. Wenigstens ist es ein Laden in meinem direkten Umfeld. Ich hätte sowieso nicht mehr runterlaufen können, denn ich war gestern schonmal unterwegs gewesen, und zweimal am Tag schaffe ich die Treppen derzeit nicht.
Das war's dann, Pearl. Die nächsten paar Jahre seht Ihr mich erstmal nicht mehr.




 Follow the White Rabbit…
Follow the White Rabbit… Dev Prompt Patterns
Dev Prompt Patterns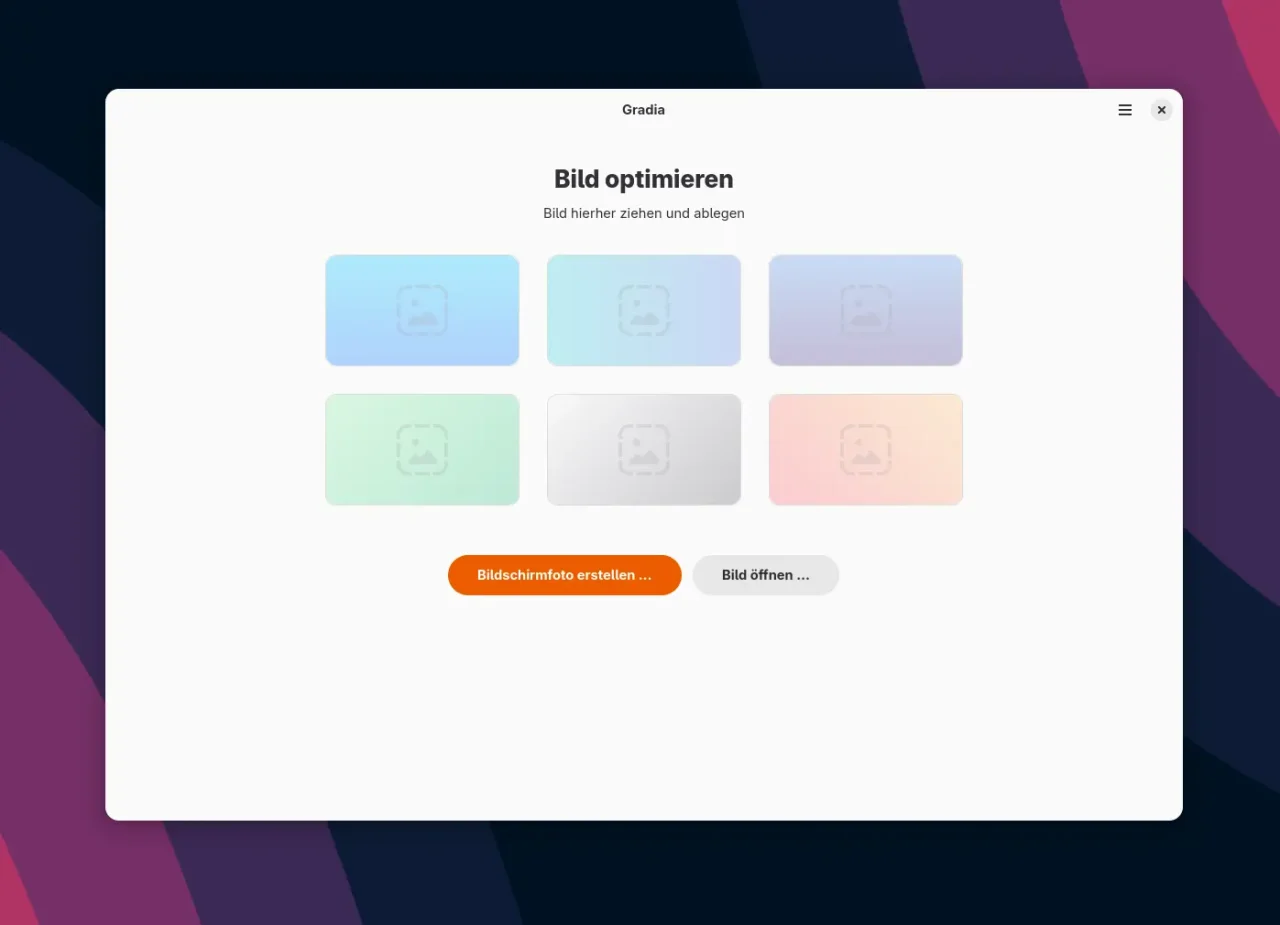 Der neue Startscreen von Gradia 1.4 zeigt eine übersichtliche Benutzeroberfläche mit direkten Optionen für Screenshots und die wichtigsten Bearbeitungsfunktionen auf einen Blick.
Der neue Startscreen von Gradia 1.4 zeigt eine übersichtliche Benutzeroberfläche mit direkten Optionen für Screenshots und die wichtigsten Bearbeitungsfunktionen auf einen Blick.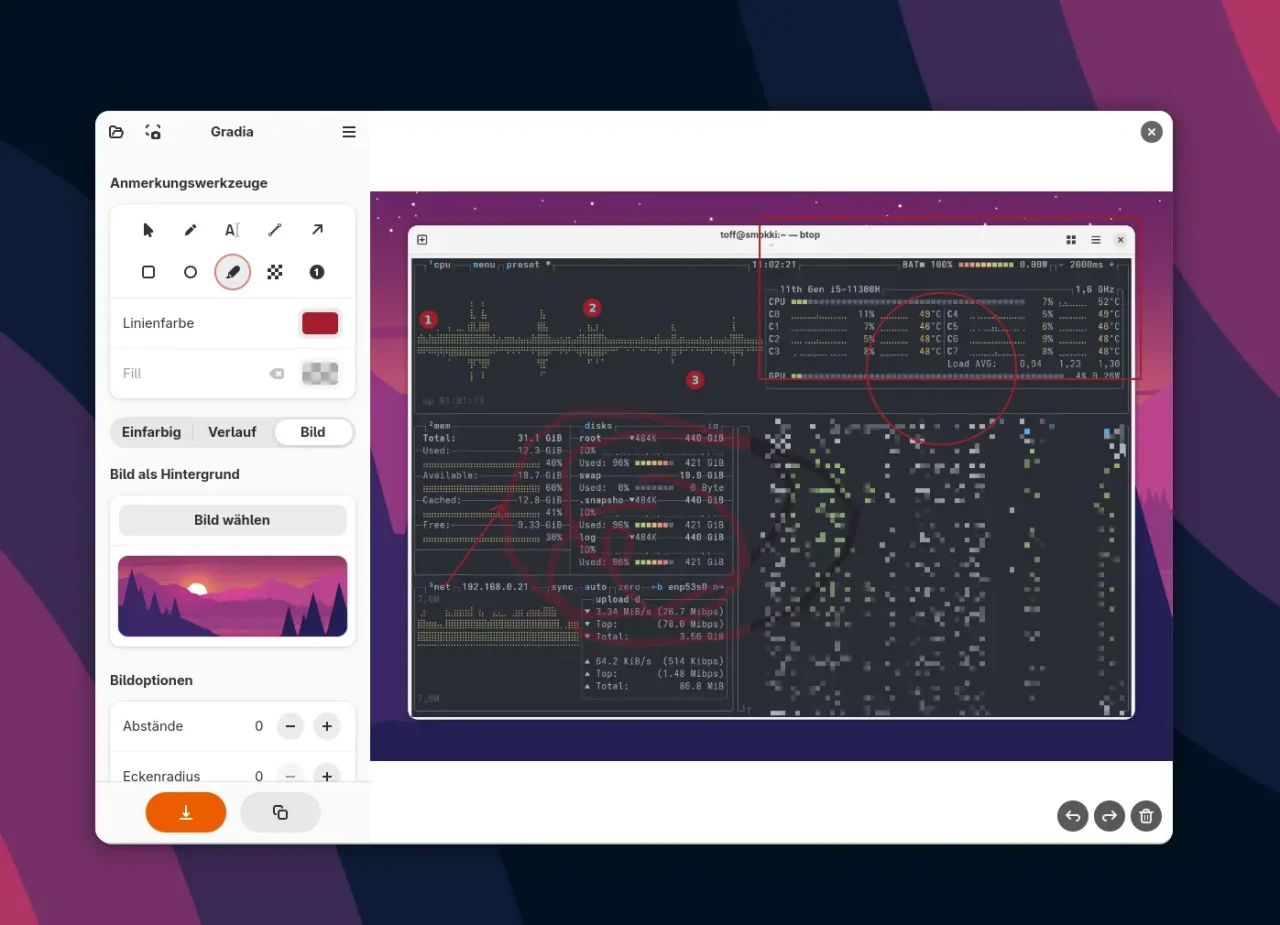 Jetzt mit vollwertigem Editor: Gradia 1.4 bietet umfangreiche Annotation-Tools wie Pfeile, Text, Formen und Hervorhebungen direkt in der Benutzeroberfläche für die Bildbearbeitung.
Jetzt mit vollwertigem Editor: Gradia 1.4 bietet umfangreiche Annotation-Tools wie Pfeile, Text, Formen und Hervorhebungen direkt in der Benutzeroberfläche für die Bildbearbeitung. Legacy (PHP) Code GPTs – Refactoring Fun
Legacy (PHP) Code GPTs – Refactoring Fun







 (PHP) Coding GPTs – Clean and Typed
(PHP) Coding GPTs – Clean and Typed Thinking Tools – Meta, Prompt Systems
Thinking Tools – Meta, Prompt Systems Disruption GPTs – Radical Clarity, No Filters
Disruption GPTs – Radical Clarity, No Filters

 Noch muss man Artikel in WordPress selber tippen oder Inhalte extern von ChatGPT und Co. aufbereiten lassen. In Zukunft will WordPress KI-Tools direkt in das CMS einbetten.
Noch muss man Artikel in WordPress selber tippen oder Inhalte extern von ChatGPT und Co. aufbereiten lassen. In Zukunft will WordPress KI-Tools direkt in das CMS einbetten.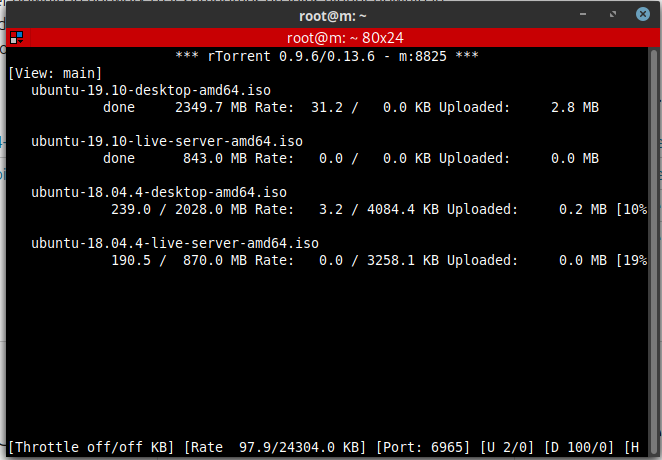
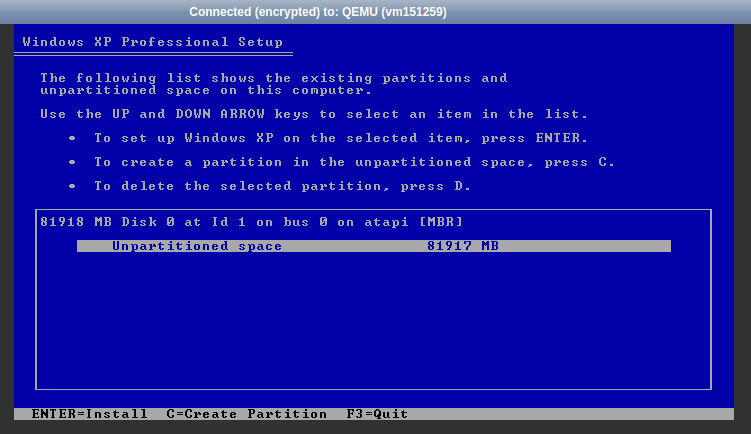
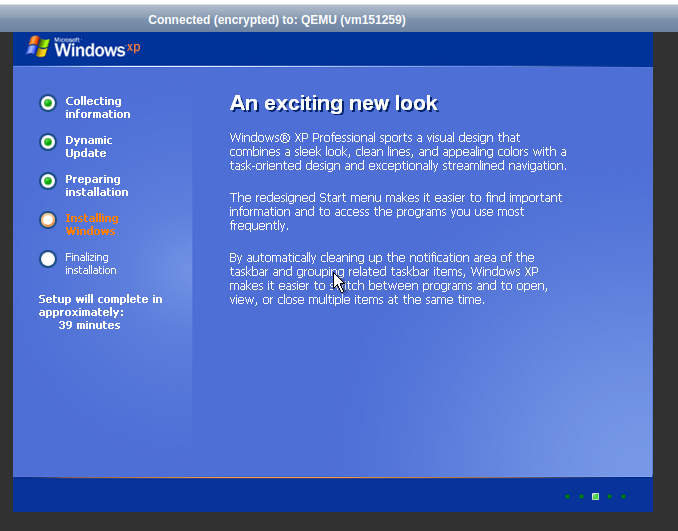
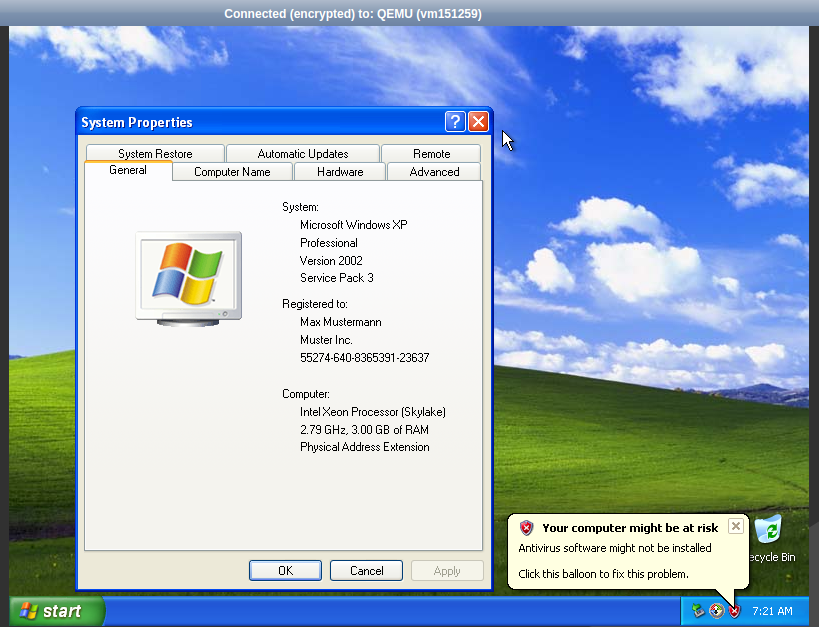
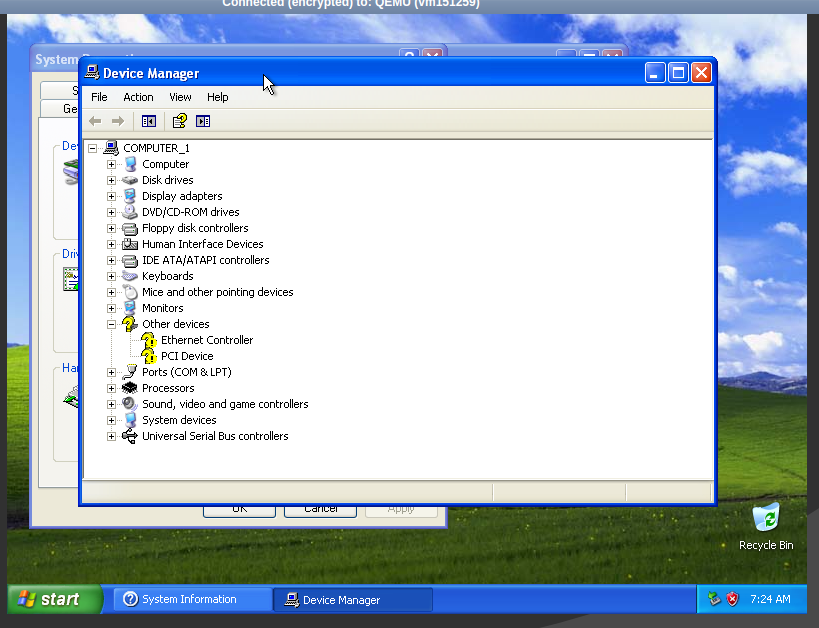
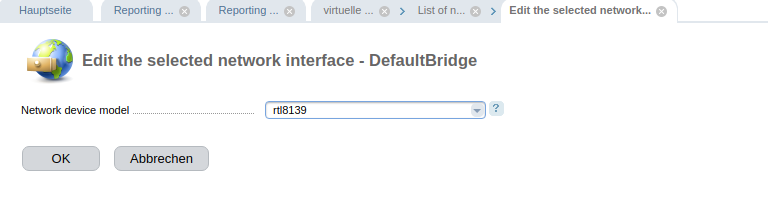


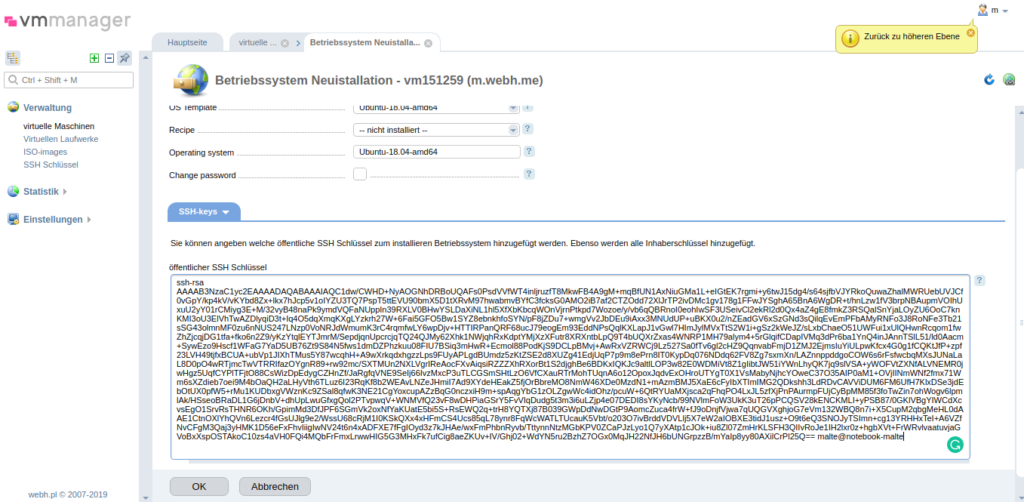
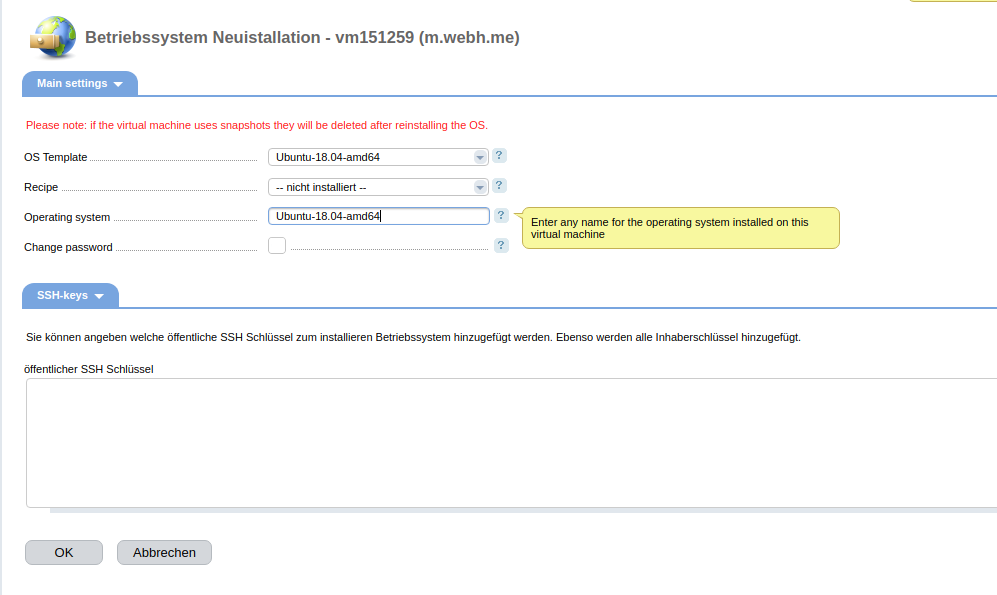

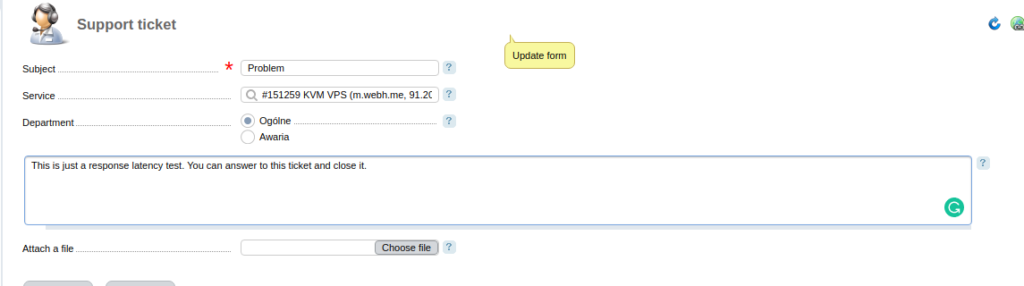
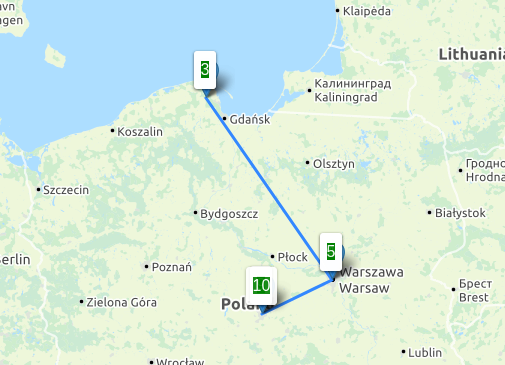
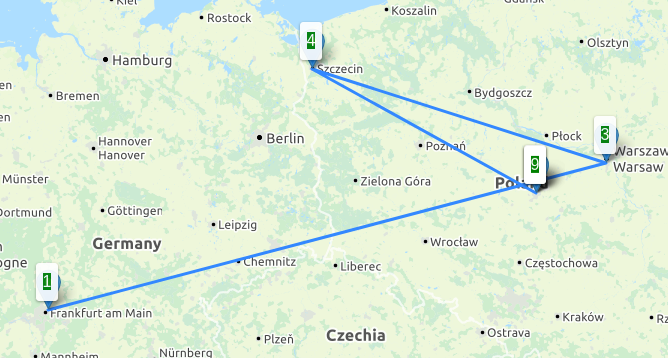
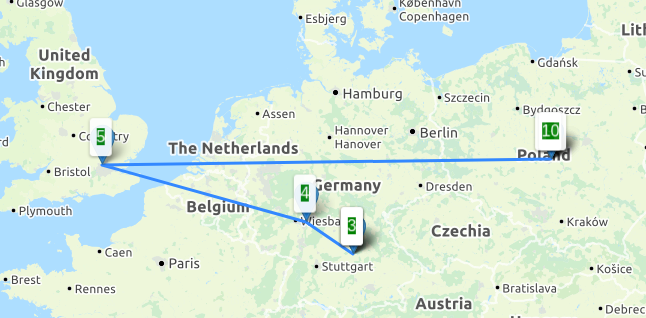
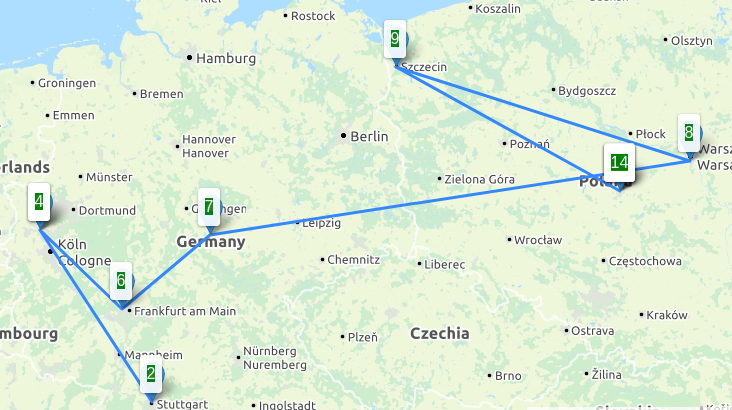
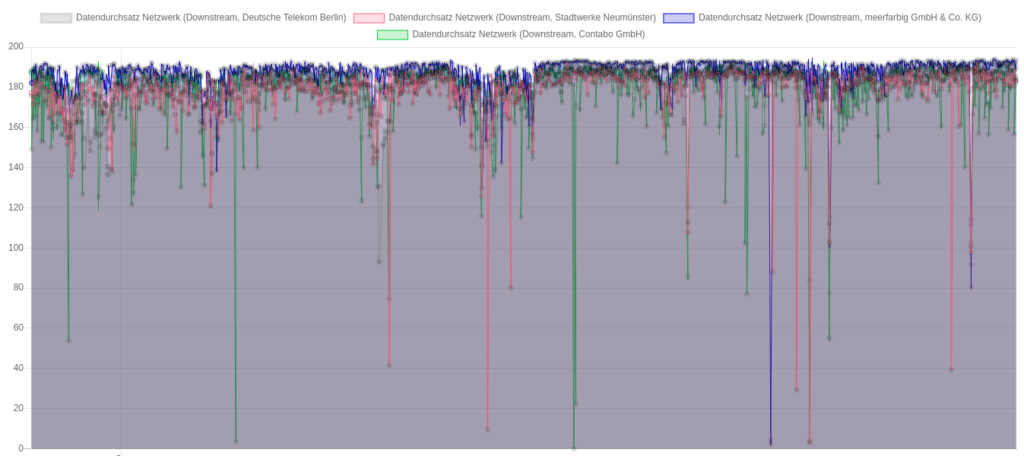 Downloadraten aus Richtung der 4 unterschiedlichen Peers, Angaben in Mbit/s
Downloadraten aus Richtung der 4 unterschiedlichen Peers, Angaben in Mbit/s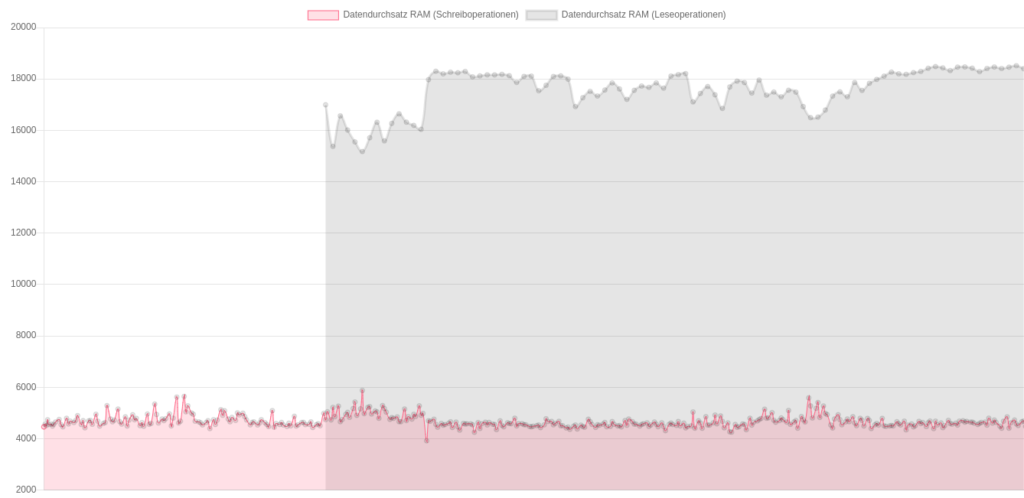 Durchsatzraten lesend und schreibend (Datenpunkte “lesend” wurden seltener und erst später gesammelt)
Durchsatzraten lesend und schreibend (Datenpunkte “lesend” wurden seltener und erst später gesammelt)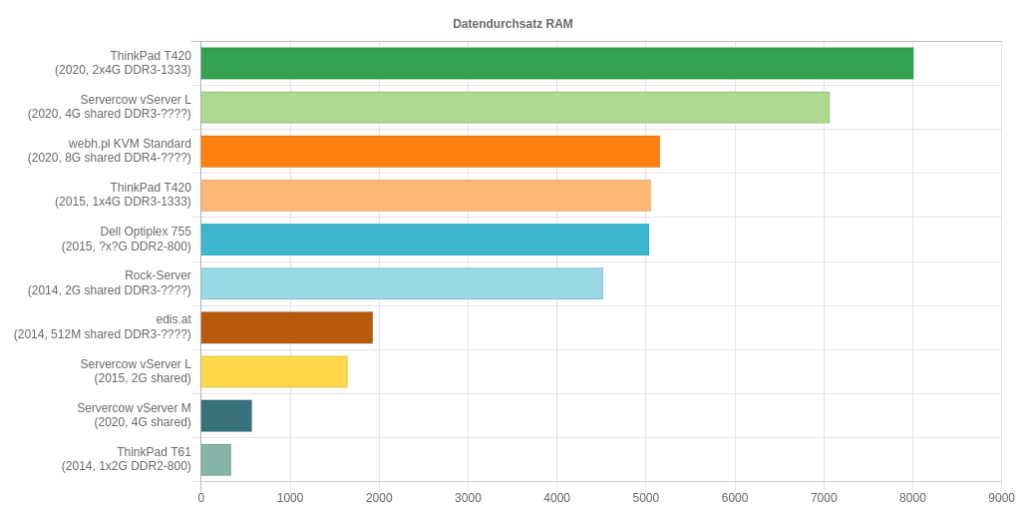
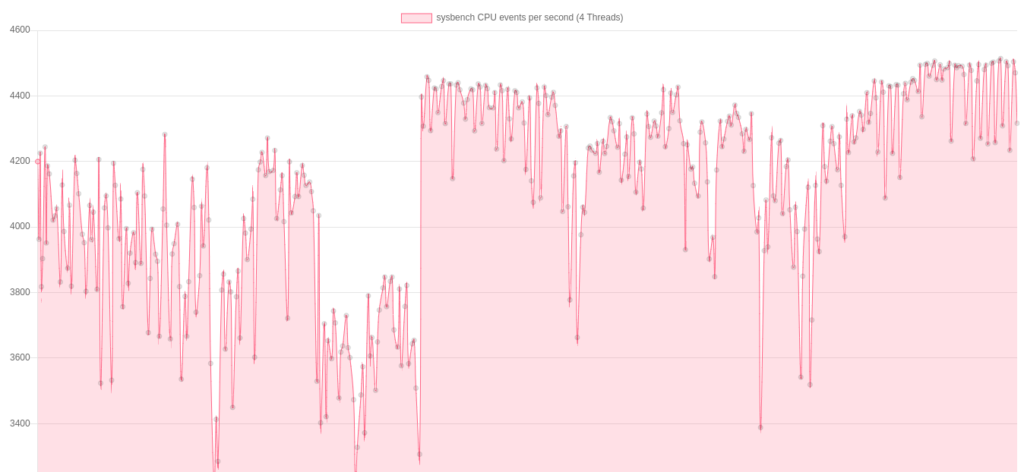 sysbench CPU Benchmark über die gesamte Testdauer
sysbench CPU Benchmark über die gesamte Testdauer










 Wie würden wohl im Wettkampf die noch ausstehenden 9km zu bewältigen sein, lies sich der Wettkampf überhaupt erfolgreich beenden? Durch die Erfahrung aus dem Frühjahr, war eigentlich klar, dass es vermutlich das
Wie würden wohl im Wettkampf die noch ausstehenden 9km zu bewältigen sein, lies sich der Wettkampf überhaupt erfolgreich beenden? Durch die Erfahrung aus dem Frühjahr, war eigentlich klar, dass es vermutlich das 







 Mein Arbeitsplatz und die verwendeten Funktechniken
Mein Arbeitsplatz und die verwendeten Funktechniken 









 -<-,–{@ Euer Darian
-<-,–{@ Euer Darian

{kind=link}