
MX Linux mit XFCE als Oberfläche funktioniert so ziemlich out of the box auf der betagten Hardware des MacBook Air 2011. Im Anschluss muss nur wenig konfiguriert werden.
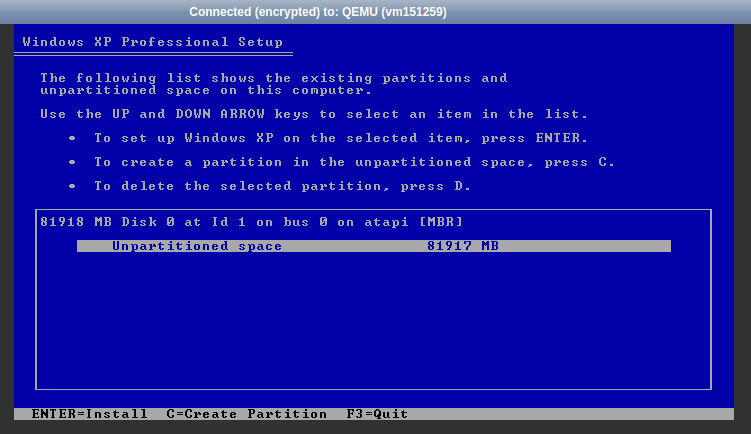
USB-Stick für die Installation booten
Nachdem das ISO heruntergeladen und mit z.B. balenaEtcher auf einen USB-Stick geschrieben wurde, wird das MacBook mit eingestecktem Stick gestartet. Dabei hält man die Option-Taste (⌥, links neben der Cmd-Taste) solange gedrückt, bis ein Boot-Menü erscheint: „EFI Boot“ (das ist der USB-Stick) mit den Pfeiltasten auswählen und Enter drücken. Das Live-Image von MX Linux bootet, aus dem heraus man dann die Installation mit „MX Linux installieren“ starten kann.
MX Linux anpassen
Nach der Installation und nachdem MX mit sudo apt update && sudo apt full-upgrade aktualisiert wurde, sollte man prüfen, ob tlp, ein Tool, das die Akkulaufzeit von Laptops optimiert, indem es verschiedene Stromspareinstellungen automatisch anwendet, installiert ist und es ggf. aktivieren:
sudo apt install tlp
sudo service tlp enable
sudo service tlp start
Anschließend kann man überprüfen, ob es läuft:
sudo service tlp status
Da das MacBook Air gerne mal sehr heiß wird, habe ich noch thermald, einen Linux-Dienst, der die Temperatur von Geräten überwacht und steuert, um Überhitzung zu verhindern, installiert:
sudo apt install thermald
Mit powertop wird der Energieverbrauch des Systems analysiert und Optimierungsvorschläge für eine längere Akkulaufzeit gegeben:
sudo apt install powertop
sudo powertop --auto-tune
Außerdem habe ich noch als Kernel-Parameter den intel_pstate auf passive gesetzt
nano /etc/default/grub
Dann den folgenden Eintrag erweitert:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash intel_pstate=passive"
Und mit sudo update-grub bestätigt.
Tastaturbelegung an das MacBook anpassen
MacBooks haben ein eigenes Tastatur-Layout, auch wenn die Sprache auf Deutsch steht. Deshalb funktioniert z.B., das @-Zeichen nicht wie erwartet. Daher habe ich das Tastatur-Layout wie folgt eingestellt:
sudo dpkg-reconfigure keyboard-configuration
Anschließend folgt man den Dialog und wählt als Tastatur-Modell: Apple Laptop. Als Variante habe ich Apple Laptop (German) gewählt. Nach den Einstellungen einfach neu starten oder das Keyboard-Layout so aktivieren:
sudo service keyboard-setup restart
sudo udevadm trigger --subsystem-match=input --action=change
Jetzt bekommt man @ wie wie es auf der Tastatur steht über die Tasten Alt + L.
Sprache einstellen
Normal sollte die Sprache nach der Installation vom MX Linux kein Problem sein, aber falls doch noch nicht die richtige Sprache eingestellt ist, kann man die Sprachpakete mit dem „MX Paket-Installer“ nachladen (findet man unter Menü / Favoriten oder unter dem Menüpunkt MX-Werkzeuge). Dann unter Sprache bei den gewünschten Paketen ein Häkchen setzen und alle weiteren Fragen mit „OK“ oder einem „J“ für Ja beantworten.
In den Einstellungen der jeweiligen Programme wie Firefox und LibreOffice muss dann noch auf Deutsch umgestellt werden. Damit XFCE in der gewünschten Sprache startet, muss die Variable LANG entsprechend gesetzt werden: export LANG=de_DE.UTF-8
Um die Änderung dauerhaft zu machen, trägt man die Zeile z.B. in der Datei ~/.profile ein.




 Follow the White Rabbit…
Follow the White Rabbit… Dev Prompt Patterns
Dev Prompt Patterns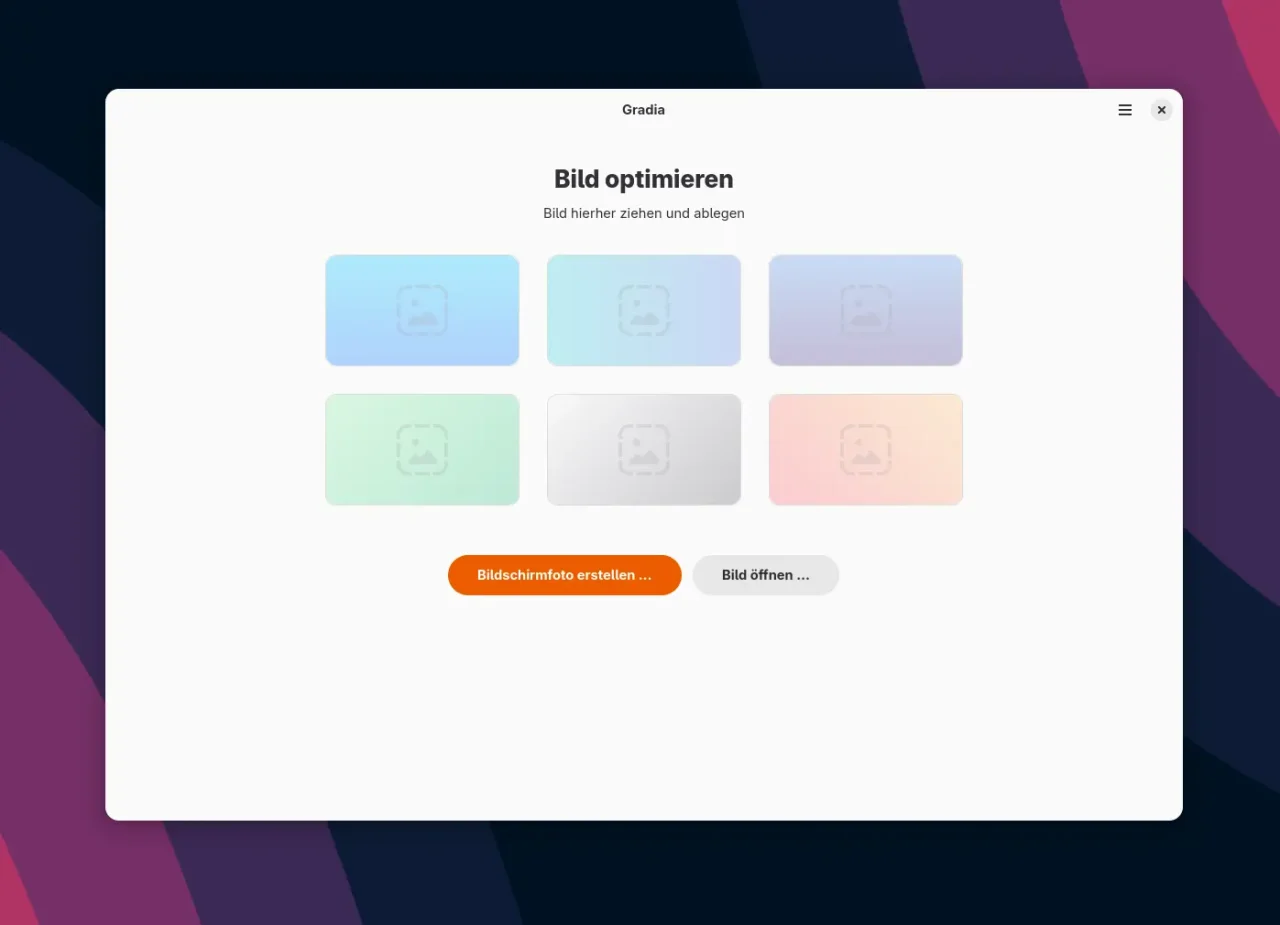 Der neue Startscreen von Gradia 1.4 zeigt eine übersichtliche Benutzeroberfläche mit direkten Optionen für Screenshots und die wichtigsten Bearbeitungsfunktionen auf einen Blick.
Der neue Startscreen von Gradia 1.4 zeigt eine übersichtliche Benutzeroberfläche mit direkten Optionen für Screenshots und die wichtigsten Bearbeitungsfunktionen auf einen Blick.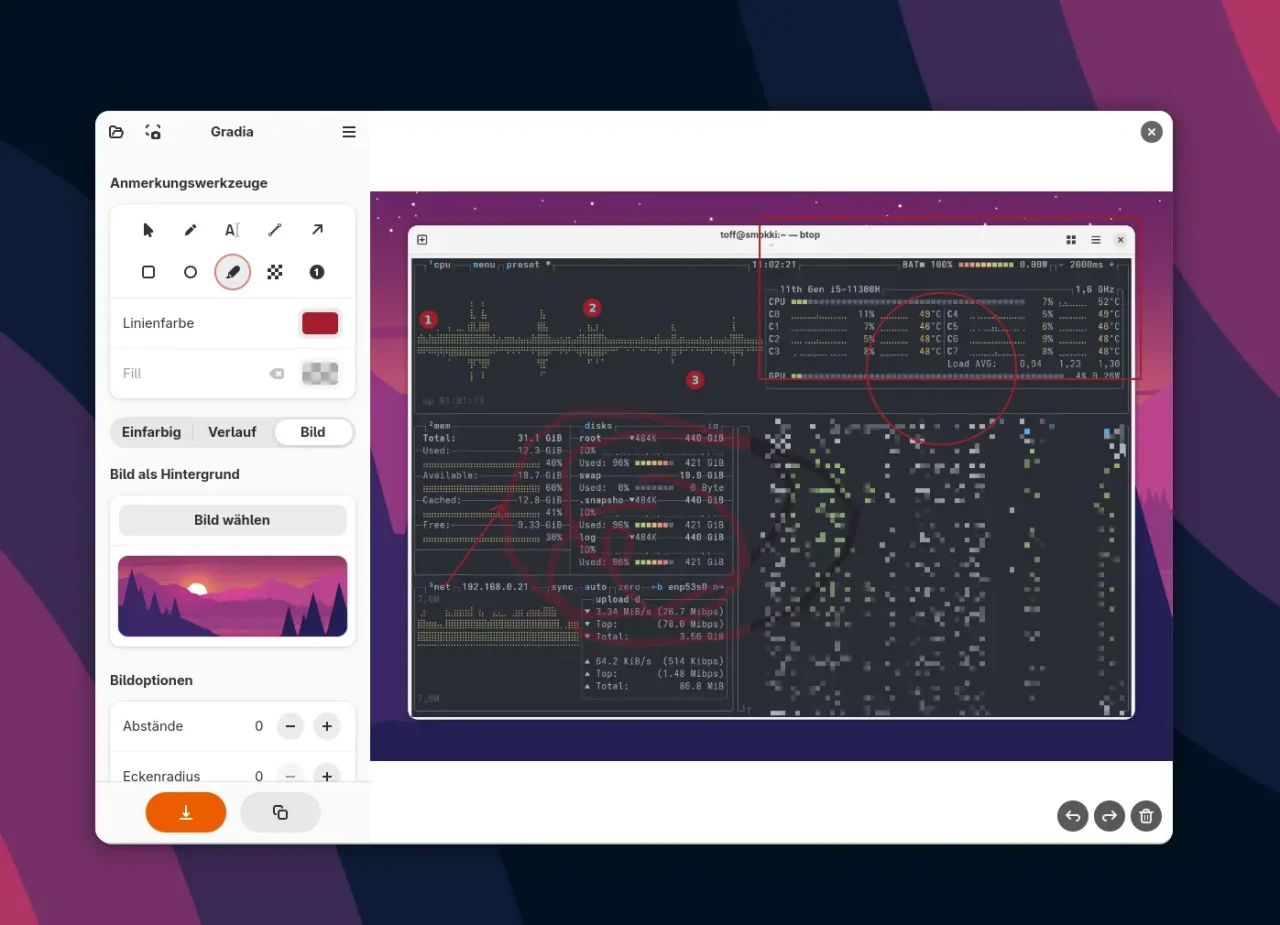 Jetzt mit vollwertigem Editor: Gradia 1.4 bietet umfangreiche Annotation-Tools wie Pfeile, Text, Formen und Hervorhebungen direkt in der Benutzeroberfläche für die Bildbearbeitung.
Jetzt mit vollwertigem Editor: Gradia 1.4 bietet umfangreiche Annotation-Tools wie Pfeile, Text, Formen und Hervorhebungen direkt in der Benutzeroberfläche für die Bildbearbeitung. Legacy (PHP) Code GPTs – Refactoring Fun
Legacy (PHP) Code GPTs – Refactoring Fun







 (PHP) Coding GPTs – Clean and Typed
(PHP) Coding GPTs – Clean and Typed Thinking Tools – Meta, Prompt Systems
Thinking Tools – Meta, Prompt Systems Disruption GPTs – Radical Clarity, No Filters
Disruption GPTs – Radical Clarity, No Filters

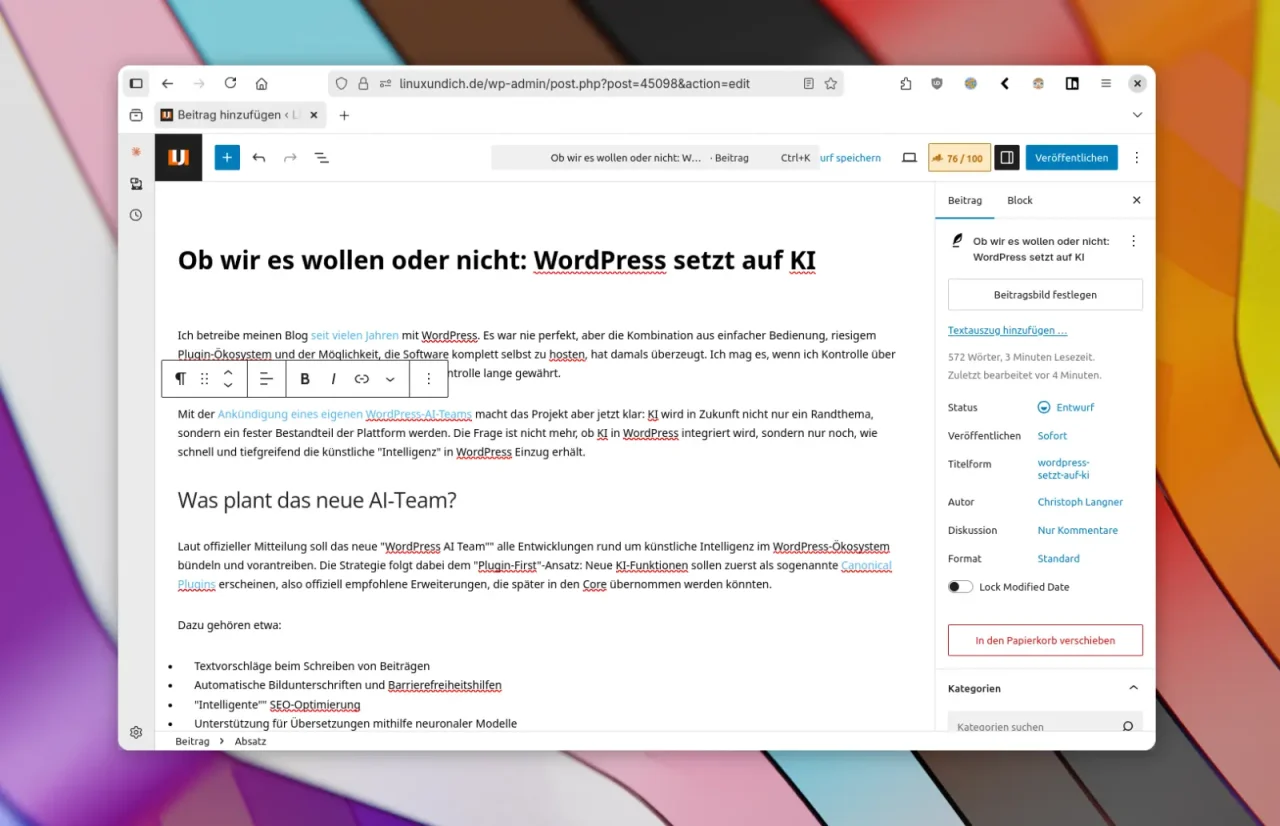 Noch muss man Artikel in WordPress selber tippen oder Inhalte extern von ChatGPT und Co. aufbereiten lassen. In Zukunft will WordPress KI-Tools direkt in das CMS einbetten.
Noch muss man Artikel in WordPress selber tippen oder Inhalte extern von ChatGPT und Co. aufbereiten lassen. In Zukunft will WordPress KI-Tools direkt in das CMS einbetten.



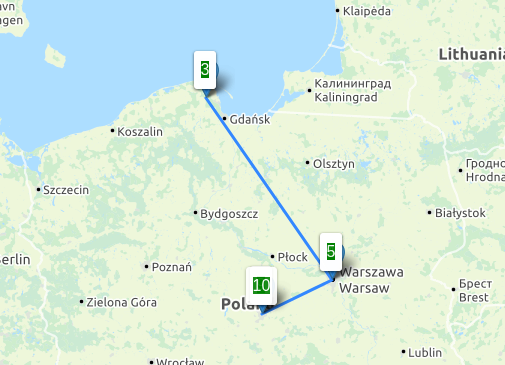
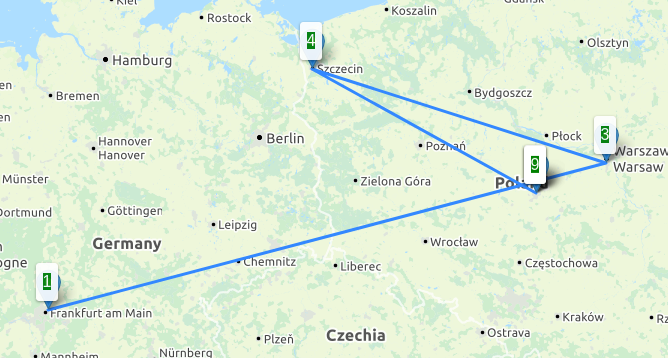
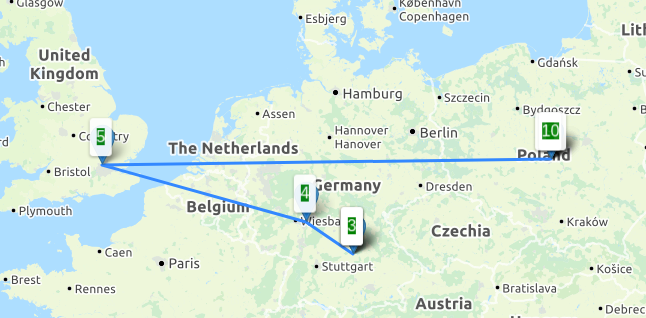
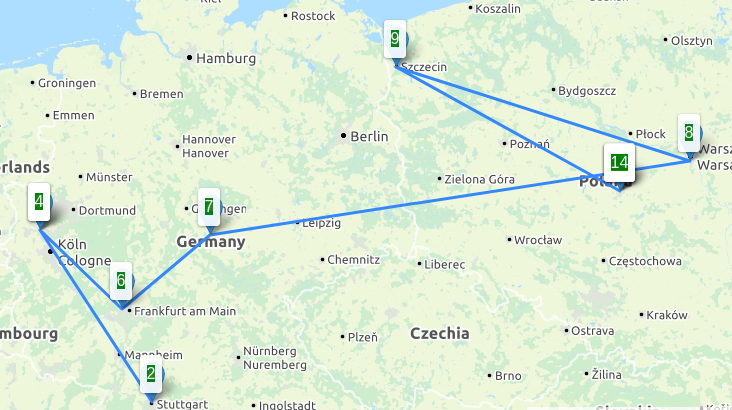
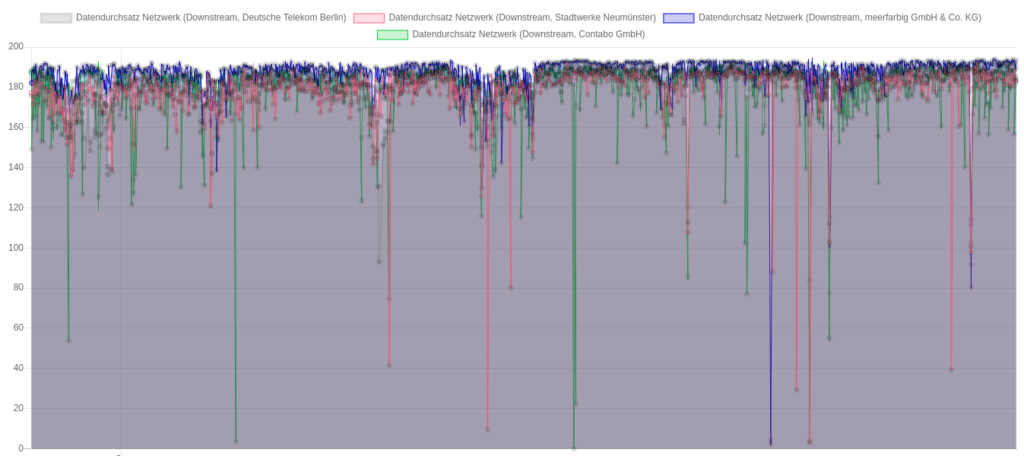 Downloadraten aus Richtung der 4 unterschiedlichen Peers, Angaben in Mbit/s
Downloadraten aus Richtung der 4 unterschiedlichen Peers, Angaben in Mbit/s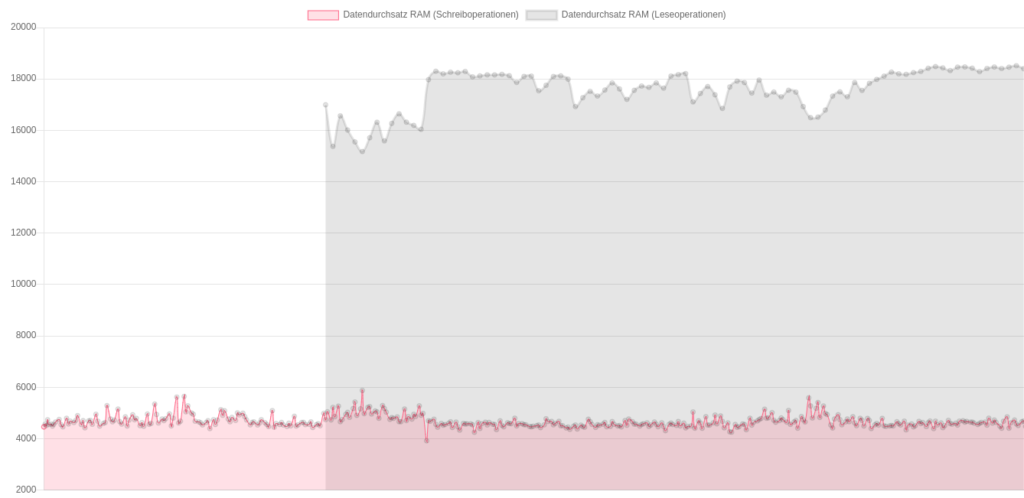 Durchsatzraten lesend und schreibend (Datenpunkte “lesend” wurden seltener und erst später gesammelt)
Durchsatzraten lesend und schreibend (Datenpunkte “lesend” wurden seltener und erst später gesammelt)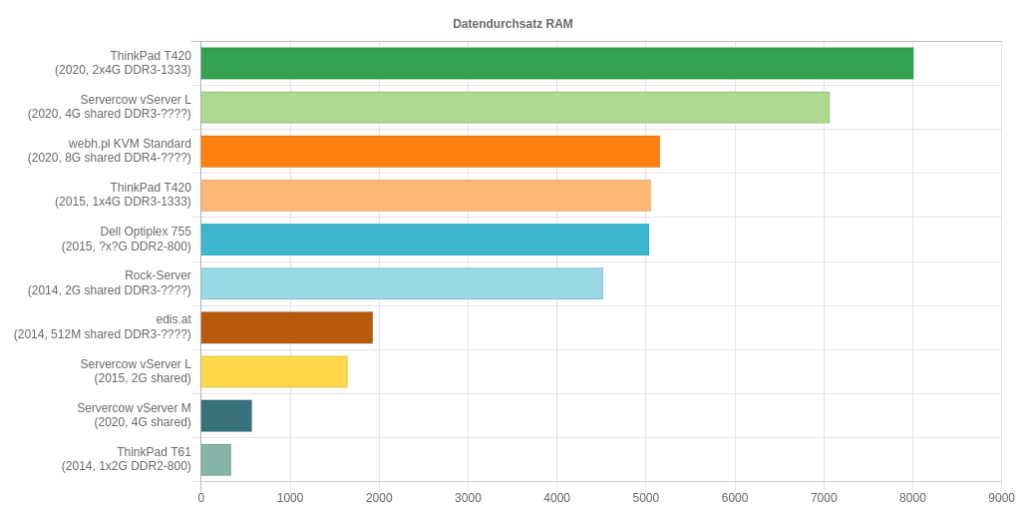
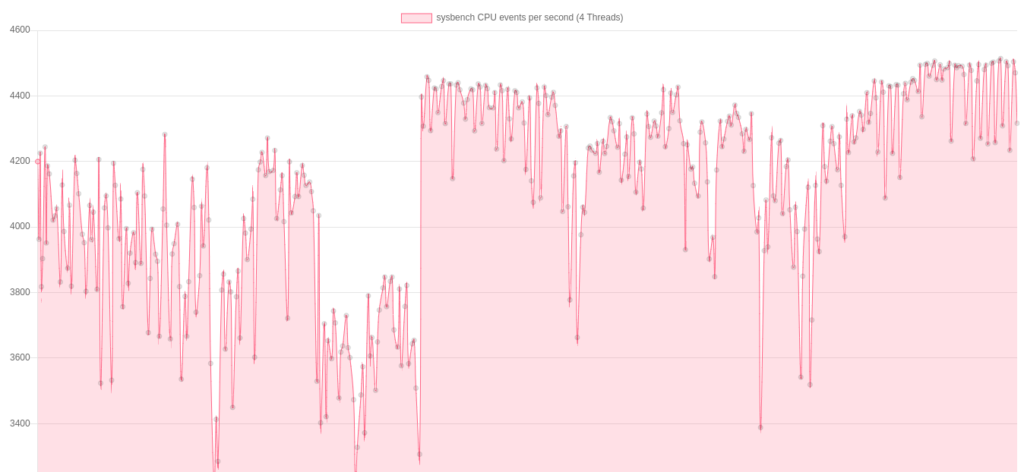 sysbench CPU Benchmark über die gesamte Testdauer
sysbench CPU Benchmark über die gesamte Testdauer



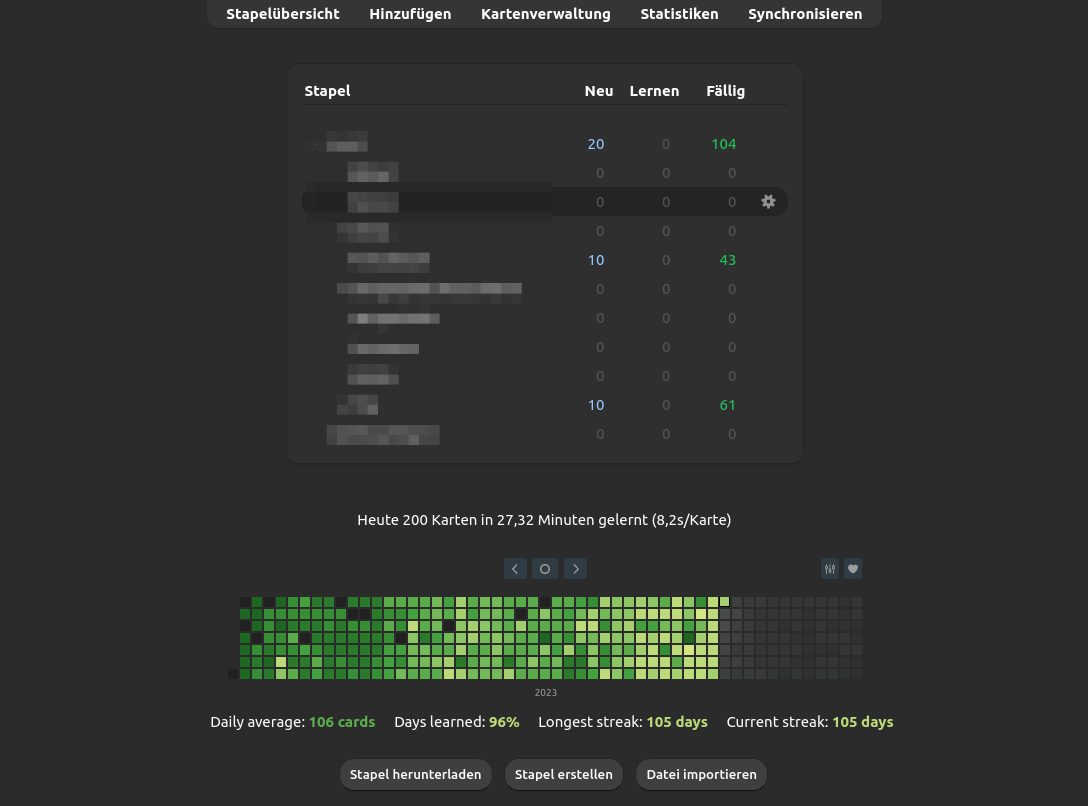







 Wie würden wohl im Wettkampf die noch ausstehenden 9km zu bewältigen sein, lies sich der Wettkampf überhaupt erfolgreich beenden? Durch die Erfahrung aus dem Frühjahr, war eigentlich klar, dass es vermutlich das
Wie würden wohl im Wettkampf die noch ausstehenden 9km zu bewältigen sein, lies sich der Wettkampf überhaupt erfolgreich beenden? Durch die Erfahrung aus dem Frühjahr, war eigentlich klar, dass es vermutlich das 







 Mein Arbeitsplatz und die verwendeten Funktechniken
Mein Arbeitsplatz und die verwendeten Funktechniken 









 -<-,–{@ Euer Darian
-<-,–{@ Euer Darian

{kind=link}